




Bevezetés a Python többszálú programozásába
Előszó
Ez a cikk a RealPython oldalon található írás fordítása. Ott találhattok egy ehhez kapcsolódó angol nyelvű videós tanfolyamot is, ami viszont fizetős.
A Python alapokról sok írás és videó található a neten és a YouTube-on magyar nyelven. A haladóbb témakörökhöz viszont már nehezebb magyar nyelvű irodalmat találni. Ezt a rést próbálom betömni evvel a cikkel is. A forráskódokat természetesen kipróbáltam és némileg magyarítottam is.
Egy összetettebb vezérlő rendszer tervezésénél úgy véltem, célravezetőbb lenne a többszálas megvalósítás. Ennek során találkoztam a fent említett cikkel. Úgy vélem, ez másoknak is segíthet elmélyülni a Python többszálas megoldásaiban.
A Thread technika lehetővé teszi, hogy a program különböző részei egyidejűleg futtassanak. Ha van némi tapasztalata a Pythonban, és fel szeretné gyorsítani a programot szálak használatával, akkor ez az oktatóanyag segítségére lesz!
Ebben a cikkben megtudhatja:
- Mi az a szál?
- Hogyan hozzunk létre szálakat és várjuk meg, amíg befejeződnek
- Hogyan kell használni a
ThreadPoolExecutorosztályt - Hogyan kerüljük el a verseny helyzetet
- A Python által biztosított gyakori
threadingeszközök használata
Ez a cikk azt feltételezi, hogy ismeri a Python alapjait és legalább a 3.6-os verziót használja a példák futtatásához.
Mi az a szál?
A szál a végrehajtás külön folyamata. Ez azt jelenti, hogy a programodnak egyszerre két dolga lesz. De a legtöbb Python 3 implementáció esetében a különböző szálak valójában nem egyszerre futnak le: csak úgy látszanak.
Csábító dolog úgy gondolni a szálazásra, mintha két (vagy több) különböző processzor dolgozna a programon, amelyek mindegyike egyidejűleg végez egy független feladatot. Ez majdnem igaz. Lehet, hogy a szálak különböző processzorokon futnak, de egyszerre csak egy.
Több feladat egyidejű futtatásához szükség van a Python nem szabványos implementációjára, a kód egy részének más nyelven történő megírására, vagy a multiprocessing használatára, amely némi többletköltséggel jár.
A Python CPython -megvalósításának módja miatt előfordulhat, hogy a szálazás nem gyorsítja fel az összes feladatot. Ennek oka a GIL-lel (Global Interpreter Lock) való interakció, amely lényegében korlátozza egy-egy Python szál futását.
Azok a feladatok, amelyek idejük nagy részét a külső eseményekre várják, általában jó jelöltek a szálakra. Azok a problémák, amelyek nagy CPU-számítást igényelnek, és kevés időt töltenek a külső eseményekre várva, egyáltalán nem futhatnak gyorsabban.
Ez igaz a Pythonban írt és a szabványos CPython implementáción futó kódokra. Ha a szálak C-ben vannak írva, akkor képesek a GIL felszabadítására és párhuzamos futtatására. Ha más Python implementációt futtat, ellenőrizze a dokumentációban is, hogyan kezeli a szálakat.
Ha szabványos Python implementációt futtat, csak Pythonban ír, és CPU-val kapcsolatos problémája van, akkor inkább nézze meg a multiprocessing modult.
A program felépítése a szálazáshoz szintén javíthatja a tervezést. Az oktatóanyagban ismertetett példák többsége nem feltétlenül fog gyorsabban futni, mert szálakat használnak.
OK, most már ne beszéljünk a szálakról, hanem inkább kezdjük el használni!
Egy Szál elindítása
Most, hogy a szál fogalmával, tanuljuk meg, hogyan készítsünk egy szálat. A Python egyik szabványos könyvtára, a threading, amely tartalmazza a cikkben látható primitívek nagy részét. Ebben a modulban található a Thread, mely szépen lezárja a szálakat, tiszta felületet biztosítva a velük való munkához.
Külön szál indításához hozzon létre egy Thread példányt, majd indítsuk el:
Python
1 import logging
2 import threading
3 import time
4
5 def thread_function(name):
6 logging.info("Thread %s: indul", name)
7 time.sleep(2)
8 logging.info("Thread %s: végzett", name)
9
10 if __name__ == "__main__":
11 format = "%(asctime)s: %(message)s"
12 logging.basicConfig(format=format, level=logging.INFO,
13 datefmt="%H:%M:%S")
14
15 logging.info("Main : a thread létrehozása előtt")
16 x = threading.Thread(target=thread_function, args=(1,))
17 logging.info("Main : miután létrejött a thread")
18 x.start()
19 logging.info("Main : várunk, hogy a thread lefusson")
20 # x.join()
21 logging.info("Main : kész")Ha megnézzük a kódot és a naplózási utasításokat, láthatjuk, hogy a main szakasz létrehozza és elindítja a szálat:
Python
x = threading.Thread(target=thread_function, args=(1,))
x.start()A létrehozásakor a Thread függvénynek átadunk egy függvényt és egy argumentumokat tartalmazó listát. Ebben a példában azt mondjuk a Thread függvénynek, hogy futtassa thread_function()és adja át az 1 értéket, mint argumentumot.
Ebben a cikkben szekvenciális egész számokat használunk a szálak nevének. Létezik a threading.get_ident() függvény, amely minden szálnak egyedi nevet ad vissza, de ezek általában nem rövidek és nehezen olvashatók.
A thread_function() önmagában nem sokat tesz. Egyszerűen naplózza az üzeneteket, amelyek között egy time.sleep() van.
Ha most a programot úgy futtatjuk, ahogy van, ( a 20-as sor kommentként szerepel), a következő kimenetet kapjuk:
Shell
19:38:25: Main : a thread létrehozása előtt
19:38:25: Main : miután létrejött a thread
19:38:25: Thread 1: indul
19:38:25: Main : várunk, hogy a thread lefusson
19:38:25: Main : kész
19:38:27: Thread 1: végzett
Process finished with exit code 0Vegyük észre, hogy a main függvény hamarabb lefut, mit a Thread 1. Ennek okára visszatérünk a következő részben, ahol a rejtélyes 20-as sorról is szó lesz.
Démonszálak
Az informatikában a démon (daemon) az a folyamat, ami a háttérben fut le.
A Phyton threading megvalósításában a démonnak speciális jelentése van. Itt a démon szál azonnal leáll, amikor a program kilép. Gondoljuk úgy az ilyen szálakra, hogy nem okoznak problémát, amikor a program kilép.
Nézzük kicsit közelebbről az előbbi program kimenetét. Azon belül is az utolsó két sort. Miután a main végzet, (kiírta a Main: kész üzenetet), 2 másodperces várakozás van, míg a thread_function is végez (megjelenik a Thread 1: végzett üzenet). Ebben a szünetben tulajdonképpen a Python arra vár, hogy a nem démoni szál lefusson. Amikor a Python program befejeződik, a leállítási rutin része a threading rutinok kitisztítása.
Ha megnézi a Python threading moduljának forráskódját, látni fogja, hogy threading._shutdown()végigmegy az összes futó szálon, és meghívja .join() metódust mindegyiken, amelyiken nincs beállítva daemon jelző.
Tehát a program várja a szálak kilépését. Amint befejezte a szál a várakozást és kinyomtatta az üzenetet, .join() visszatér, és a program kiléphet.
Gyakran ezt a viselkedést szeretnénk, de más lehetőségek is rendelkezésünkre állnak. Először futtassuk ismét a programot, de most egy daemon szállal. Ezt úgy teheti meg, hogy megváltoztatja a Thread létrehozását, hozzáadja a daemon=True jelzőt:
Python
x = threading.Thread(target=thread_function, args=(1,), daemon=True)
Ha most lefuttatjuk a programot, ezt a kimenetét látjuk:
Shell
17:56:22: Main : a thread létrehozása előtt
17:56:22: Main : miután létrejött a thread
17:56:22: Thread 1: indul
17:56:22: Main : várunk, hogy a thread lefusson
17:56:22: Main : kész
Process finished with exit code 0A különbség itt az, hogy a kimenet utolsó sora hiányzik, thread_function()nem kapott lehetőséget a befejezésre. Ez egy daemon szál volt, így amikor __main__elérte a kód végét, és a program befejeződött, a démon szál futása is befejeződött anélkül, hogy a futása a végéhez érjen.
join() a szálon
A démonszálak praktikusak, de mi van akkor, ha meg akarod várni a szál leállítását? Mi van akkor, ha csak akkor akarsz kilépni a programból, ha már lefutott a szál? Most térjünk vissza az eredeti programhoz (vegyük ki a daemon=True jelzőt), és nézzük a megjegyzést tartalmazó húszas sort:
Python
# x.join()
Ha azt akarja, hogy várjuk meg, amíg egy szál befejeződik, hívja meg rajta a .join() függvényt. Ha megszünteti a megjegyzést, a fő szál megáll, és megvárja, amíg az x szál befejeződik.
Tesztelje le, hogy teljes mindegy, az adott szál démon szál e, vagy sem. A join() függvény mindenféleképpen megvárja, míg az adott szál befejeződik.
Munka több szállal
A példakód eddig csak két szállal működött: a fő szállal és azzal az egyel, amit az threading.Thread objektummal kezdtél. Remélem ide érve már nem lepődsz meg azon, hogy a program is egy szál.
Gyakran előfordul, hogy egy adott feladat elvégzéséhez több szálat kell indítani. Ennek két módja van. Egy könnyebb és egy nehezebb.
Kezdjük a nehezebbel, mert ez már ismerős.
Python
1 import logging
2 import threading
3 import time
4
5 def thread_function(name):
6 logging.info("Thread %s: indul", name)
7 time.sleep(2)
8 logging.info("Thread %s: végzett", name)
9
10 if __name__ == "__main__":
11 format = "%(asctime)s: %(message)s"
12 logging.basicConfig(format=format, level=logging.INFO,
13 datefmt="%H:%M:%S")
14
15 threads = list()
16 for index in range(3):
17 logging.info("Main : létrehozása és indítása a %d szálnak.", index)
18 x = threading.Thread(target=thread_function, args=(index,))
19 threads.append(x)
20 x.start()
21
22 for index, thread in enumerate(threads):
23 logging.info("Main : mielőtt meghívnánk a %d szálon a join()-t.", index)
24 thread.join()
25 logging.info("Main : a %d szál befejeződött.", index)
Ez a kód ugyanazt a mechanizmust használja, amelyet fent látott egy szál elindításához, egy Thread objektum létrehozásához, majd az indításához a .start() függvénnyel. A program listát vezet a Thread objektumokról, hogy aztán később megvárhassa a befejeződésüket a .join()függvény segítségével..
Ennek a kódnak a többszörös futtatása valószínűleg érdekes eredményeket hozhat. Íme egy példa a gépemről:
Shell
18:36:10: Main : létrehozása és indítása a 0 szálnak.
18:36:10: Thread 0: indul
18:36:10: Main : létrehozása és indítása a 1 szálnak.
18:36:10: Thread 1: indul
18:36:10: Main : létrehozása és indítása a 2 szálnak.
18:36:10: Thread 2: indul
18:36:10: Main : mielőtt meghívnánk a 0 szálon a join()-t.
18:36:12: Thread 2: végzett
18:36:12: Thread 1: végzett
18:36:12: Thread 0: végzett
18:36:12: Main : a 0 szál befejeződött.
18:36:12: Main : mielőtt meghívnánk a 1 szálon a join()-t.
18:36:12: Main : a 1 szál befejeződött.
18:36:12: Main : mielőtt meghívnánk a 2 szálon a join()-t.
18:36:12: Main : a 2 szál befejeződött.
Process finished with exit code 0Ha végignézi a kimenetet, látni fogja, hogy mindhárom szál az elvárt sorrendben indul, de ebben az esetben az ellenkező sorrendben fejeződnek be! Több futtatás különböző rendeléseket eredményez.
A szálak futtatásának sorrendjét az operációs rendszer határozza meg, és elég nehéz megjósolni. Ez futásonként változhat (és valószínűleg változni is fog), ezt tudnia kell, amikor olyan algoritmust tervez, amely szálakat használ.
Szerencsére a Python számos primitívet kínál, amelyeket később megnézünk, amelyek segítenek összehangolni a szálakat és összekapcsolni őket. Előtte nézzük meg, hogyan lehet egy kicsit egyszerűbbé tenni egy szálcsoport kezelését.
A ThreadPoolExecutor használata
Van egy egyszerűbb módja annak, hogy egy szálcsoportot indítsunk, mint amit fent látott. Ez a ThreadPoolExecutor osztály, és a szabványos concurrent.futures könyvtár része (a Python 3.2 verziója szerint).
Létrehozásának legegyszerűbb módja a környezetkezelő, a with utasítás használatával.
Íme, a legutóbbi példa, amelyet a következőképpen írjunk át a ThreadPoolExecutor használatához:
Python
1 import logging
2 import concurrent.futures
3 import time
4
5 def thread_function(name):
6 logging.info("Thread %s: indul", name)
7 time.sleep(2)
8 logging.info("Thread %s: végzett", name)
9
10 if __name__ == "__main__":
11 format = "%(asctime)s: %(message)s"
12 logging.basicConfig(format=format, level=logging.INFO,
13 datefmt="%H:%M:%S")
14
15 with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
16 executor.map(thread_function, range(3))
A kód létrehoz egy ThreadPoolExecutor-t kontextuskezelőként, és megmondja, hogy hány szálat szeretne a készletben. Ezután .map()függvény egy iteráláson megy végig, jelen esetében range(3)-on, mindegyikkel létrehozva egy szálat.
Az így létrehozott szálak rögtön el is indulnak és egy join() hívást is kapnak. Tehát a with blokk utáni kódok csak akkor futnak le, ha a szálak futása befejeződött.
Megjegyzés: A ThreadPoolExecutor használata zavaró hibákat okozhat.
Például, ha meghív egy függvényt, amely nem vesz paramétereket, de megadja a paramétereket .map() metódusnak, a szál kivételt dob.
Sajnos ThreadPoolExecutor elrejti ezt a kivételt, és (a fenti esetben) a program kimenet nélkül fejeződik be. Ez elsőre elég zavaró lehet a hibakeresésben.
Ennek a kódnak a kimenete így fog kinézni:
Shell18:57:51: Thread 0: indul
18:57:51: Thread 1: indul
18:57:51: Thread 2: indul
18:57:53: Thread 2: végzett
18:57:53: Thread 1: végzett
18:57:53: Thread 0: végzett
Process finished with exit code 0
ismételten vegyük észre, hogy a szálak befejezése előre nem megjósolható sorrendben fog történni. Ezek kezelését az operációs rendszer végzi.
Versenyfeltételek
Mielőtt továbblépnénk a Python további threading elemeihez, beszélnünk kell egy problémáról, amit az angol irodalom versenyhelyzetnek (race conditions) nevez. Ezen versenykörülmények elkerülését csak akkor tudjuk megoldani, ha megértjük, mi is az a versenyfeltétel, mitől alakul ki.
A versenyfeltételek akkor fordulhatnak elő, ha két vagy több szál hozzáfér egy megosztott adathoz vagy erőforráshoz. Ebben a példában egy nagy versenyfeltételt fog létrehozni, amely minden alkalommal megtörténik. Ne feledje, hogy a legtöbb versenykörülmény nem ilyen nyilvánvaló. Gyakran csak ritkán fordulnak elő, és zavaros eredményeket hozhatnak. És ez bizony eléggé megnehezíti a hibakeresést.
Szerencsére ez a példabeli versenyfeltétel minden alkalommal megtörténik, és részletesen végigjárható, hogy elmagyarázzuk, mi történik.
Ebben a példában egy olyan osztályt fog írni, amely frissíti az adatbázist. Rendben, nem igazán lesz adatbázisod: csak utánozni fogod, mert nem ez a cikk lényege.
Tehát a FakeDatabase ami tartalmazza az __init__() és az update() metódusokat:
Python
class FakeDatabase:
def __init__(self):
self.value = 0
def update(self, name):
logging.info("Thread %s: update indul", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.info("Thread %s: update végzett", name)
Nézzük meg közelebbről ezt az osztályt. Egy változót tartalmaz, ez pedig a value. Ez lesz a megosztott adat, amelyen látni fogja a verseny állapotát.
Az __init__() metódus egy dolgot tesz, nullázza a value állapotát.
Az update() metódus kicsit furán néz ki. Ez szimulálja egy érték olvasását egy adatbázisból, néhány számítást végez rajta, majd új értéket ír vissza az adatbázisba.
A példaosztályunkban az adatbázis írása/olvasása a value írását/olvasását jelenti. A néhány számítás konkrétan az érték 1-el való növelését jelenti, majd egy kicsit várakozunk.
Ezt a FakeDatabase-t következőképpen fogja használni :
Python
if __name__ == "__main__":
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO,
datefmt="%H:%M:%S")
database = FakeDatabase()
logging.info("update tesztelése. Kezdő érték: %d.", database.value)
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
for index in range(2):
executor.submit(database.update, index)
logging.info("update tesztelése. Érték lefutás után: %d.", database.value)
Ez a program létrehoz 2 szálat, majd mind a kettőn futtatja a Database.update() metódusát, a submit hívásával.
A submit() létrehoz egy szálat, aminek megadható, hogy melyik metódus fusson szálként és ennek argumentumai is megadhatóak.
Python
submit(fuction, *args, **kwargs)
A fenti példában csak egy argumentumot adunk át a database.update-nek. Ez az index. Később látni fogjuk, hogy több értéket is átadhatunk.
Mivel ez a példa két szálat futtat, mindkettőn a database.update-et, arra számítanánk, hogy a program lefutása után a database.value értéke 2-lesz. Már sejtheted, hogy ha ez így lenne, nem foglalkoznánk vele.
Futtasuk a kódot, a következő kimenetet fogjuk kapni:
10:35:26: update tesztelése. Kezdő érték: 0.
10:35:26: Thread 0: update indul
10:35:26: Thread 1: update indul
10:35:26: Thread 1: update végzett
10:35:26: Thread 0: update végzett
10:35:26: update tesztelése. Érték lefutás után: 1.
Process finished with exit code 0Egy szál
Mielőtt kielemeznénk a problémát, elemezzük hogy, hogyan is működik egy szál. Nem fogunk részletesen belemerülni. Néhány dolgot leegyszerűsítünk, nem lesz technikailag pontos, de jó és érthető képet ad arról, mi is történik.
Amikor azt mondjuk a ThreadPoolExecutor-nak, hogy futtatunk egy szálat, meg határozni, hogy melyik függvényt/metódust futtassa és milyen paramétereket továbbítson neki: executor.submit(database.update, index)
A példában minden szál futtatja a database.update(index) metódust. Vegye figyelembe, hogy a database a __main__ főszálon lett létrehozva, egy FakeDatabase osztályból. Az update() ennek a példánynak egy metódusát hívja meg.
Minden szár ugyanarra a FakeDatabase objectumra fog hivatkozni, a database-ra. Ezenfelül minden szálnak lesz egy egyedi értéke, az index, hogy a naplózás könnyebb legyen.

Amikor a szál elindítja az update() metódust, minden helyi adatnak saját verziója van. A mi esetünkben ez a local_copy. Ez megakadályozza, hogy az egyidejűleg futó, de ugyanazt a metódust futtató szálak adatai összekeveredjenek. Ez azt jelenti, hogy minden változó, aminek egy függvényre van hatóköre (vagy helyi) szálbiztos.
Ezen alapok után most nézzük meg, mi történik, ha a felni programmal egy szálat és csak egyszer hívjuk meg az update() metódust.
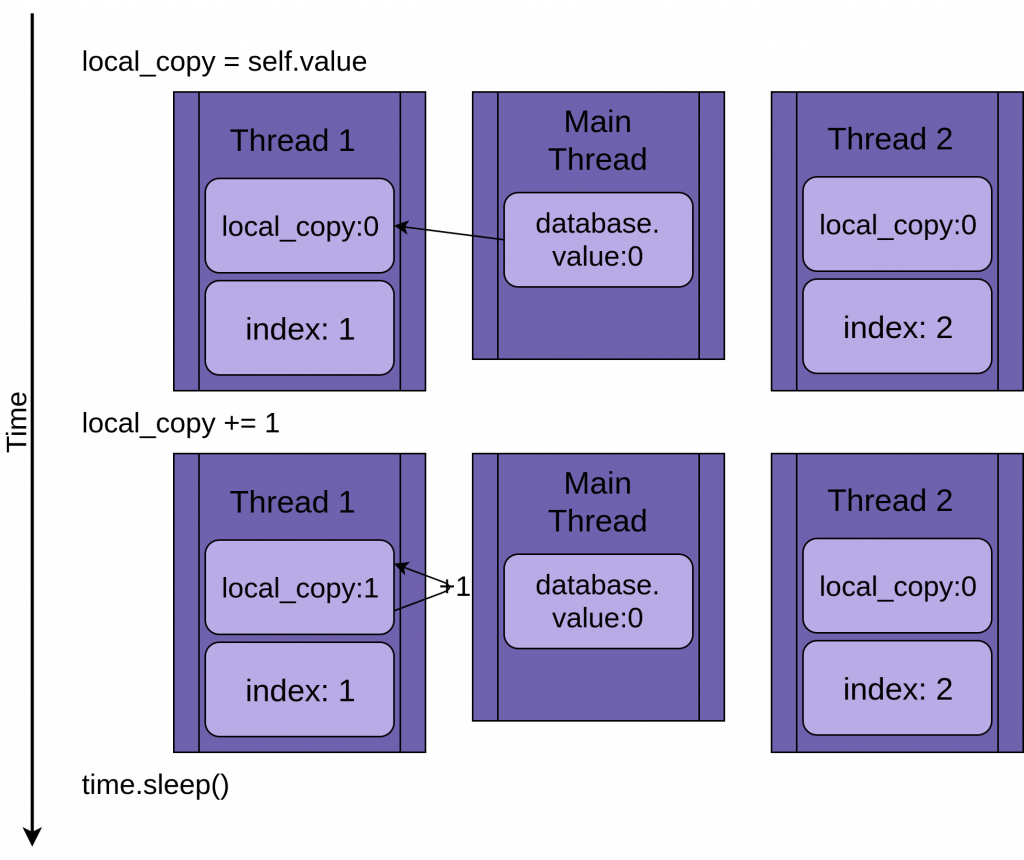
A következő kép azt mutatja, hogyan fut le az update() metódus. Bal oldalt láthatjátok az utasításokat, alatta egy diagramot, hogy hogyan alakul a helyi local_copy és a megosztott value értéke.

database.update() lefutásaA diagramon a metódus futása időrendnek megfelelően látható. Legfelül a Thread 1 létrehozásakori állapot, legalul pedig a megszünésekorit.
Amikor Thread 1 elindul, a FakeDatabase.value értéke nulla. Az első sor ezt az értéket átmásolja a lokális (helyi) változóba, a local_copy-ba. A következő sor, ezt az értéket megnöveli egyel. Ezután a time.sleep() metódussal várakozunk egy kicsit. Ezzel szimuláljuk, hogy még további műveletek lehetnek az adatbázissal. Mivel most csak egy szál fut, jelen pillanatban nincs jelentősége.
Miután letelt a várakozási idő, a local.copy értékát átmásoljuk a FakeDatabase.value változóba.
Eddig mindig úgy alakul, ahogy terveztük. Lefut a szál és a FakeDatabase.value értéke 1 lett.
Két szál
Visszatérve a verseny állapotához, a két szál párhuzamosan fut, de nem egyszerre. Mindegyiknek megvan a saját verziója a local_copy -ról, és mindegyik ugyanazt a database-t használja. Ez a megosztott database objektum okozza a problémákat.
A program a Thread 1 update() hívásával indul:
Amikor az 1. szál elér a time.sleep() parancs hívásához, akkor lehetővé teszi a másik szál futását. Itt kezdenek érdekessé válni a dolgok.
A második szál elindul és ugyanazokat a műveleteket hajtja végre, mind az első. Az-az a saját local_copy változójába másolja a database.value értékét, miközben az még nem frissült:
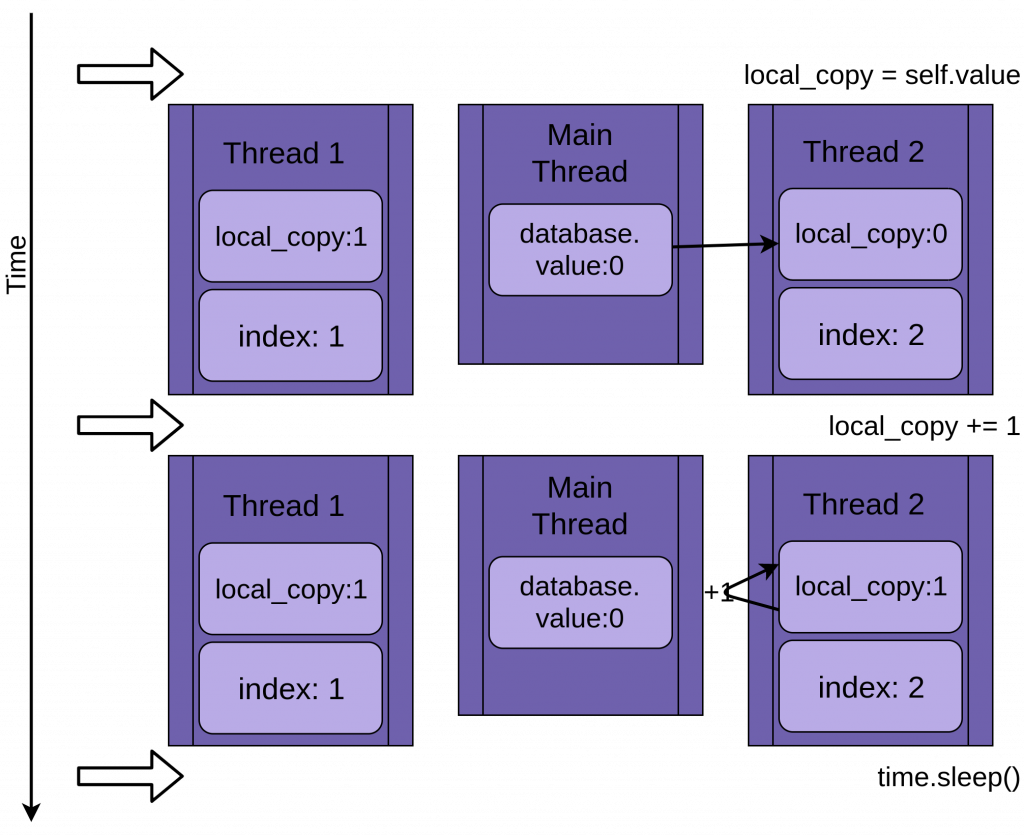
Amikor a Thread 2 is eléri a time.sleep() utasítást, a database.value értéke még mindig nulla, és mind a két szál local_copy változójának értéke 1.
Az 1. szál most felébred, és átmásolja a local_copy tartalmát a database.value-ba , majd leáll. Ezután a 2. szál is végrehajtja a hátralévő utasításait. A 2. szálnak fogalma sincs arról, hogy az 1. szál futott és frissítette a database.value értékét, amíg várt. A local_copy verzióját tárolja az database.value értékben, és egyre állítja:

A két szál egyidejű hozzáféréssel rendelkezik egyetlen megosztott objektumhoz, felülírva egymás eredményeit. Hasonló versenyfeltételek adódhatnak, ha az egyik szál memóriát szabadít fel, vagy bezárja a fájlkezelőt, mielőtt a másik szál végezne.
Ez miért nem buta példa
A fenti példa mesterkélt annak biztosítására, hogy a versenyfeltétel minden alkalommal megtörténjen, amikor a programot futtatja. Mivel az operációs rendszer bármikor kicserélheti a szálat, lehetőség van egy olyan utasítás megszakítására, mint az x = x + 1, miután kiolvasta az x értékét, de még mielőtt visszaírná a megnövelt értéket.
Ennek részletei meglehetősen érdekesek, de a cikk további részeinek megértéséhez nem szükségesek.
Most, hogy megértettük a problémát, nézzük meg, hogyan lehet megoldani.
Alap szinkronizálás a Lock() használatával
Számos módja van a fenti probléma elkerülésének megoldására. Itt most természetesen nem fogjuk mindet bemutatni. Viszont vannak olyan általános megoldások, amiket gyakran használnak. Ezek közül kezdjük a Lock-al.
A fenti versenyfeltételek megoldásához meg kell találnia a módját, hogy egyszerre csak egy szálat engedjen be az olvasás-módosítás-írás szakaszába a kód. Ennek leggyakoribb módja a Python-ban a Lock. Más nyelvekben ugyanezt az elképzelést mutexnek hívják. A Mutex a MUTual EXclusion -ból (kölcsönös kizárás) származik, pontosan ez az, amit a Lock is csinál.
A Lock egy blokkot képez a szálon belül. A Lock-olt kódrészen csak egy szál dolgozhat. Ha egy másik szál már fut benne, meg kell várni, míg az a szál végez. A lock egyébként zárat jelent, tehát hú a nevéhez. Lezárja a kódrészt a a többi szál elől.
Ennek alapvető funkciói az acquire () és az release (). Egy szál a my_lock.acquire() metódus hívásával zárolja a blokkot. Ha a zárolás már meg volt egy másik szálon, a hívó szál megvárja, amíg amíg az felold. Van itt egy fontos pont. Ha egy szál zárolja a kódot, de soha nem oldja fel, a program elakad. Erről később még lesz szó.
Szerencsére a Python-ban Lock környezetkezelőként is működik, így használható a with utasítással, így automatikusan felszabadul, ha a blokkból bármilyen okból kilép a Lock.
Egészítsük ki a FakeDatabase-t a Lock-al. A hívó kód természetesen változatlan marad:
Python
class FakeDatabase:
def __init__(self):
self.value = 0
self._lock = threading.Lock()
def update(self, name):
logging.info("Thread %s: update indul", name)
logging.debug("Thread %s zárolása", name)
with self._lock:
logging.debug("Thread %s zárólva", name)
local_copy = self.value
local_copy += 1
time.sleep(0.1)
self.value = local_copy
logging.debug("Thread %s feloldva", name)
logging.info("Thread %s: update végzett", name)
Azon kívül, hogy egy csomó hibakeresési naplózást adunk hozzá, hogy tisztábban láthassuk a zárolást, a nagy változás itt az ._lock nevű tag hozzáadása, ami egy threading.Lock() objektum. Ezt a _lock-ot nyitott állapotban inicializálja, és a with utasítással zárja, majd felszabadítja.
Vegyük észre, hogy ez a szál mindig tartani fogja a zárat, amíg az adatbásísból olvas, módosít és visszaírja az adatokat.
Ha ezt a verziót warning (figyelmeztetés) szintre állított naplózással futtatja, akkor ezt fogja látni:
Shell
15:42:20: update tesztelése. Kezdő érték: 0.
15:42:20: Thread 0: update indul
15:42:20: Thread 1: update indul
15:42:20: Thread 0: update végzett
15:42:20: Thread 1: update végzett
15:42:20: update tesztelése. Érték lefutás után: 2.
Process finished with exit code 0Most már szépen lefut a program, azt a végeredményt kaptuk, amit szeretünk volna.
A teljes naplózást úgy kapcsolhatja be, hogy a naplózási szintet DEBUG -ra állítja, ha hozzáadja ezt az utasítást, miután konfigurálta a naplózási kimenetet a __main__ -ban:
Python
logging.getLogger().setLevel(logging.DEBUG)
Ha most elindítja a programot a DEBUG naplózási szinttel, a következő kimenetet kapja:
Shell
16:03:01: update tesztelése. Kezdő érték: 0.
16:03:01: Thread 0: update indul
16:03:01: Thread 0 zárolása
16:03:01: Thread 0 zárólva
16:03:01: Thread 1: update indul
16:03:01: Thread 1 zárolása
16:03:01: Thread 0 feloldva
16:03:01: Thread 1 zárólva
16:03:01: Thread 0: update végzett
16:03:01: Thread 1 feloldva
16:03:01: Thread 1: update végzett
16:03:01: update tesztelése. Érték lefutás után: 2.
Process finished with exit code 0Ezen a kimeneten jól látható, hogy elindul Thread 0, megszerzi a zárat, majd várakozik szépen. Ezalatt a Thread 1 is elindul és szeretné megszerezni a a zárat. De mivel azt a Thread 0 már megszereznte, várnia kell. Miután a Thread 0 végzet és oldja a zárat, a Thread 1 folytathatja a kód végrehajtását. Ez a kölcsönös kizárás, amit a Lock biztosít.
A cikk további részeiben található példakódokban WARNING és DEBUG naplózási szinteket is használni fogunk. Mivel a DEBUG naplózási szint általában nagyon megnöveli az üzenetek számát, általában WARNING szintet fogunk használni. Próbálja ki a különböző naplózási szinteket.
Holtpont
Mielőtt továbblépne, nézzen meg egy gyakori problémát a Lock használatakor. Amint látta, ha a zárat már megszerezte, akkor az acquire() második hívása megvárja, amíg a zárat tartó szál meg nem hívja a release() metódust. Mit gondol, mi történik, ha ezt a kódot futtatja:
Python
import threading
l = threading.Lock()
print("A acquire hívása előtt")
l.acquire()
print("A acquire második hívása elött")
l.acquire()
print("Készer megszerzett zár")
Amikor a program másodszor is meghívja az l.acquire() parancsot, lefagy, és várja a zár feloldását (l.release()). Ebben a példában a holtpontot a második hívás eltávolításával lehet kijavítani, de a holtpont általában a következő két dolog egyikéből következik be:
- Megvalósítási hiba, a zárat nem oldják fel.
- Tervezési probléma, amikor egy segédfügvényt olyan fügvényeknek kell meghívniuk, amelyek már rendelkeznek zárral.
Az első eset néha előfordul, de a Lock használata környezetkezelőként jelentősen csökkenti annak gyakoriságát. Mint azt már említettem, a környezetkezelők használatával ajánlott kódot írni, amikor csak lehetséges, mivel ezek segítenek elkerülni azokat a helyzeteket, amikor kimarad egy release() hívást.
A tervezési hiba kérdése néhány nyelv esetében kissé bonyolultabb lehet. Szerencsére a Python szálkezelésnek van egy második objektuma, az RLock, amelyet pont erre a helyzetre terveztek. Lehetővé teszi, hogy egy szál többször is meghívja az acquire() metódust egy RLock-on, mielőtt meghívja a release() metódust.
Ennek a szálnak még mindig ugyanannyiszor kell meghívnia a release()-t, ahányszor az acquire()-t hívta, de ezt egyébként is meg kell tennie.
A Lock és az RLock két alapvető eszköz a szálprogramozásban a versenyfeltételek elkerülésére. Vannak még más megoldások is, amelyek más-más módon működnek. Mielőtt megnézzük őket, térjünk át egy kicsit más problématerületre.
Producer-Consumer szálazás
A Producer-Consumer (Termelő – Fogyasztó) probléma egy alap informatikai probléma, amelyet a szálak vagy folyamatok szinkronizálási problémáinak vizsgálatára használnak. Ennek egy változatát fogod megnézni, hogy legyen elképzelése arról, hogy a Python szálkezelő modul milyen primitíveket biztosít.
Ebben a példában egy olyan programot fogunk elképzelni, amelynek adatokat kell beolvasnia a hálózatról, és kiírnia őket a lemezre. A program nem akkor kér adatot, amikor akar.
Figyelnie kell és fogadnia az adatokat és amikor azok beérkeznek, üzenetek formályában továbbytasni.. Az adatok nem egyenletes ütemben, hanem szakaszossan fognak érkezni. A programnak ezt a részét nevezzük producernek (termelő).
A másik oldalon, ha már van egy üzenet, akkor azt egy adatbázisba kell írni. Az adatbázis-hozzáférés lassú, de elég gyors ahhoz, hogy lépést tartson az üzenetek átlagos ütemével. Nem elég gyors ahhoz, hogy lépést tartson, amikor hirtelen érkeznek az üzenetek. Ez a rész a consumer (fogyasztó).
A termelő és a fogyasztó között létrehozunk egy Pipline-t (csővezeték), amely a két rész között szinkronizálja az adatmozgást.
Ez az alapvető elrendezés. Nézzünk meg egy megoldást a Lock használatával. Nem működik tökéletesen, de olyan eszközöket használ, amelyeket már ismerünk, így jó kiindulópont lehet.
Producer-Consumer a Lock használatával
Mivel ez a cikk a Python szálakról szól, és mivel az imént megismerkedtünk a Lock primitíel, próbáljuk meg megoldani ezt a problémát két szál segítségével, egy vagy két Lock használatával.
A következő példa felépítése az, hogy van egy termelő szál, amelyik a hamis hálózatról olvas, és az üzenetet egy Pipeline-ba helyezi:
Python
import random
SENTINEL = object()
def producer(pipeline):
"""A For ciklussal utánozzuk a hálózatról érkező üzeneteket"""
for index in range(10):
message = random.randint(1, 101)
logging.info("A Producer üzenetet kapot: %s", message)
pipeline.set_message(message, "Producer")
# Egy jelző (sentinel) üzenetet küldünk a fogyasztónak, hogy végeztünk.
pipeline.set_message(SENTINEL, "Producer")
Hogy létrehozzunk egy hamis üzenetet, a producer generál egy számot, 1 és 100 között. Ezzel meghívjuk a pipline send_message() metódusát, hogy elküldjük az üzenetet a consumer-nek.
A producer egy SENTINEL értéket is küld a tíz adat után, hogy jelezze a fogyasztónak, nincs több adat, leálhat. Ez így egy kicsit bnyolúltnak tünik, de a példa végére érve megtudjuk, hogyan tudunk megszabadúlni tölle.
A pipline másik oldalán a consumer áll:
Python
def consumer(pipeline):
"""Itt utánozzuk az adatok adatbázisba írását."""
message = 0
while message is not SENTINEL:
message = pipeline.get_message("Consumer")
if message is not SENTINEL:
logging.info("Consumer tárolja az üzenetet: %s", message)
A consumer kiólvassa az üzenetet a pipline-ból és beírja a hamis adatbázisba, ami itt most a képernyőre írást jelenti a logging-on keresztől. Majd mikór megkapja SENTINEL jelzőt, befejeződik a szál futása.
Mielőtt megnéznéd az igazán érdekes részt, a Pipeline-t, nézzük át a __main__ szakaszt, ami ezeket a szálakat létrehozza:
Python
if __name__ == "__main__":
msg_format = "%(asctime)s: %(message)s"
logging.basicConfig(format=msg_format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline)
executor.submit(consumer, pipeline)
Ez azért már elég ismerős, már többszőr is indítottunk el szálakat.
Ne feledje, bekapcsólhatja DEBUG naplózást, ha látni szeretné az összes üzenetet. Ehez elég, ha kikommenteli a következő sórt:
Python
# logging.getLogger().setLevel(logging.DEBUG)
Érdemes lehet átnézni a DEBUG naplózási üzeneteket, hogy pontosan lássuk, az egyes szálak hol veszik fel és hol adják le a zárakat.
Most nézzük meg a Pipline osztályt (csővezeték), amely az üzeneteket továbbítja a termelőtől a fogyasztóhoz:
Python
class Pipeline:
"""
Osztály, amely lehetővé teszi a termelő és a fogyasztó közötti egyelemű csővezetéket:
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
logging.debug("%s:get lock megszerzése elött", name)
self.consumer_lock.acquire()
logging.debug("%s:get lock megszerezve", name)
message = self.message
logging.debug("%s:set lock elengedése előtt", name)
self.producer_lock.release()
logging.debug("%s:set lock elengedve", name)
return message
def set_message(self, message, name):
logging.debug("%s:set lock megszerzése elött", name)
self.producer_lock.acquire()
logging.debug("%s:set lock megszerezve", name)
self.message = message
logging.debug("%s:get lock elengedése elött", name)
self.consumer_lock.release()
logging.debug("%s:get lock elengedve", name)
Ez már több kódnak néz ki. Igazáből nagy százaléka naplózási utasítás, hogy jobban nyomon követhető legyen, mi is tőrténik. Nézzük meg mégegyszer ugyanezt a kódot, a naplózási utasítások nélkül:
Python
class Pipeline:
"""
Osztály, amely lehetővé teszi a termelő és a fogyasztó közötti egyelemű csővezetéket:
"""
def __init__(self):
self.message = 0
self.producer_lock = threading.Lock()
self.consumer_lock = threading.Lock()
self.consumer_lock.acquire()
def get_message(self, name):
self.consumer_lock.acquire()
message = self.message
self.producer_lock.release()
return message
def set_message(self, message, name):
self.producer_lock.acquire()
self.message = message
self.consumer_lock.release()
Így azért már kicsit olvashatóbb. A Pipline ezen változatában 3 változóval rendelkezik:
message, tárólja az átadandó üzenetet.poducer_lock, egythreading.Lockobjektum, amely korlátozza aprocuder(termelő) szál hozzáférését az üzenethez.consumer_lock, egythreading.Lockobjektum, amely korlátozza aconsumer(fogyasztó) szál hozzáférését az üzenethez.
A init() metódus inicializálja ezt a három tagot, majd meghívja az acquire() metódust a consumer_lock-on. Ez az az állapot, amelyben indítani szeretnénk az osztályt. A producer új üzenetet adhat hozzá, de a fogyasztónak meg kell várnia, amíg egy üzenet érkezik. Ezért zároljuk az üzenet olvasását.
A get_message() és a set_messages() metódusok szinte ellentétei egymásnak. A get_message() meghívja a acquire() funkciót a consumer_lock-on. Ez az a hívás, amely arra készteti a fogyasztót, hogy várjon, amíg egy üzenet nem jön.
Miután a fogyasztó megszerezte a consumer_lock-ot, kimásolja az message-ben lévő értéket, majd meghívja a release() metódust a producer_lock-on. A zár feloldása teszi lehetővé, hogy a producer eltárólja a következő üzenetet a csővezetékbe.
Mielőtt továbbmennénk a set_message() metódusra, a get_message() metódusban történik valami olyan finom dolog, amit könnyű kihagyni. Csábítónak tűnhet, hogy kihadjuk a message helyi változót, és a függvényt a return self.message-el fejezzük be. Próbáld meg kitalálni, hogy miért nem ezt tettük, mielőtt továbblépnél.
Itt a válasz. Amint a fogyasztó meghívja a producer_lock.release() metódust, a termelő elindulhat és ki lehet cserélni a self.message tartalmát. Ez már azelőtt megtörténhet, hogy a release() visszatérne! Ez azt jelenti, hogy van egy kis esély arra, hogy amikor a függvény visszaadja a self.message-t, az valójában a következő generált üzenet lesz, így elveszítjük az első üzenetet. Ez egy másik példa a versenyfeltételre.
A set_message() metódusra továbblépve láthatjuk a tranzakció másik oldalát. A producer ezt egy üzenettel hívja meg. Megszerzi a producer_lock-ot, beállítja a self.message-t, majd meghívja a release() parancsot a consumer_lock-on. Ez lehetővé teszi a consumer számára, hogy kiolvassa ezt az értéket.
Futtassuk le a kódot, amelynek naplózása WARNING szintre van állítva, és nézzük meg, hogyan néz ki:
Shell
19:42:30: A Producer üzenetet kapot: 61
19:42:30: A Producer üzenetet kapot: 78
19:42:30: Consumer tárolja az üzenetet: 61
19:42:30: A Producer üzenetet kapot: 48
19:42:30: Consumer tárolja az üzenetet: 78
19:42:30: A Producer üzenetet kapot: 7
19:42:30: Consumer tárolja az üzenetet: 48
19:42:30: A Producer üzenetet kapot: 65
19:42:30: Consumer tárolja az üzenetet: 7
19:42:30: A Producer üzenetet kapot: 67
19:42:30: Consumer tárolja az üzenetet: 65
19:42:30: A Producer üzenetet kapot: 47
19:42:30: Consumer tárolja az üzenetet: 67
19:42:30: A Producer üzenetet kapot: 60
19:42:30: Consumer tárolja az üzenetet: 47
19:42:30: A Producer üzenetet kapot: 27
19:42:30: Consumer tárolja az üzenetet: 60
19:42:30: A Producer üzenetet kapot: 4
19:42:30: Consumer tárolja az üzenetet: 27
19:42:30: Consumer tárolja az üzenetet: 4
Process finished with exit code 0Elsőre furcsának tűnhet, hogy a producer két üzenetet kap, mielőtt a consumer egyáltalán elindulna. Ha visszanézzük a producert és a set_message() metódust, akkor észrevehetjük, hogy az egyetlen hely, ahol Lock-ra vár. Az az, amikor megpróbálja az üzenetet a csővezetékbe helyezni. Ez azután történik, hogy a producer megkapja az üzenetet és naplózza, hogy az nála van.
Amikor a producer megpróbálja elküldeni a második üzenetet, másodszor is meghívja a set_message() metódust. Mivel a Lock már zárólva lett az előző üzenet elhelyezésekór, vár annak feloldására.
Az operációs rendszer bármikor cserélheti a szálakat, de általában minden szálnak hagy egy ésszerű időtartamot a futásra, mielőtt kicserélné őket. Ezért a consumer általában addig fut, amíg a set_message() második hívásakor blokkol.
Ez azért van, mert ha egy szál blokkolva van, az operációs rendszer mindig kicseréli azt, keres egy másik szálat, amelyet futtathat. Ebben az esetben az egyetlen másik szál, aminek dolga van, az a consumer.
A consumer meghívja a get_message() metódust, amely beolvassa az üzenetet. Majd ezután meghívja a release() metódust a producer_lock-on, így a következő szálcsere alkalmával a producer újra futhat.
Vegyük észre, hogy az első üzenet 61 volt, és a comsumer pontosan ezt olvasta, annak ellenére, hogy a producer már létrehozta a 78-as üzenetet.
Bár ez a korlátozott teszt esetében működik, általánosságban nem jelent jó megoldást a termelő-fogyasztó problémára, mivel egyszerre csak egyetlen értéket enged a csővezetékben. Amikor a termelő egy csomó üzenetet kap, nem lesz hova tennie őket.
Térjünk át egy jobb megoldási módra, a Queue használatára.
Producer-Consumer a Queue használatával
Ha egyszerre egynél több értéket szeretne kezelni a csővezetékben, akkor olyan adatszerkezetre lesz szüksége a csővezetékhez, amely lehetővé teszi, hogy a tárolt adatok száma növekedjen és csökkenjen abban az ütemben, ahogy a producer írja és a consumer olvassa.
A Python standard könyvtárában van egy queue modul, amely rendelkezik egy Queue osztállyal. Változtassuk meg a Pipeline-t úgy, hogy egy Queue-t használjon egy Lock által védett változó helyett. A munkaszálak leállításának is más módját fogjuk használni, a Python szálkezelés egy másik primitívjének, az Event-nek a használatával.
Kezdjük az Eventtel. A threading.Event objektum lehetővé teszi, hogy egy szál jelezzen egy eseményt, miközben sok más szál várhat az esemény bekövetkeztére. Ebben a kódban használt tulajdonsága az, hogy az eseményre váró szálaknak nem feltétlenül kell abbahagyniuk, amit éppen csinálnak, csak időnként ellenőrizhetik az Event állapotát.
Az esemény kiváltása sokféle lehet. Ebben a példában a főszál egyszerűen alszik egy ideig, majd meghyvja az event.set() metódust:
Python
if __name__ == "__main__":
msg_format = "%(asctime)s: %(message)s"
logging.basicConfig(format=msg_format, level=logging.INFO,
datefmt="%H:%M:%S")
# logging.getLogger().setLevel(logging.DEBUG)
pipeline = Pipeline()
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: set event beállítása")
event.set()
Az egyetlen változás itt az event objektum létrehozása, az event paraméterként való átadása a szálak számára, valamint az utolsó 3 sór, amely egy másodpercet alszik, naplóz egy üzenetet, majd meghívja az event.set() metódust.
A producernek sem kellett túl sokat változtatnia:
Python
def producer(pipeline, event):
"""Utánozzuk a hálózatról érkező üzeneteket"""
while not event.is_set():
message = random.randint(1, 101)
logging.info("A Producer üzenetet kapot: %s", message)
pipeline.set_message(message, "Producer")
logging.info("Producer EXIT üzenetet kapot. Leáll")
Most addig fog futni a ciklus, amíg az event-et be nem állítjuk. A SENTINEL értéket többé nem használjuk.
A consumer is változik egy kicsit:
Python
def consumer(pipeline, event):
"""Itt utánozzuk az adatok adatbázisba írását."""
while not event.is_set() or not pipeline.empty():
message = pipeline.get_message("Consumer")
logging.info(
"Consumer tárolja az üzenetet: %s (queue mérete: %s)",
message,
pipeline.qsize()
)
logging.info("Consumer EXIT üzenetet kapot. Leáll")
Míg a SENTINEL értékkel kapcsolatos kódot ki kellett vennie, egy kissé bonyolultabb while feltételt kellett végrehajtania. Nemcsak addig kell futnia a ciklusnak, amíg az event nem lesz beállítva, hanem addig is, amíg a csővezeték ki nem ürül.
Ha meggyőződünk róla, hogy a sor üres, mielőtt a consumer befejezi a műveletet, megelőzhetünk egy másik vicces problémát. Ha a consumer kilép, miközben a csővezetékben üzenetek vannak, két rossz dolog történhet. Az első az, hogy elveszítjük az utolsó üzeneteket, de a súlyosabb, hogy a producer fennakadhat azon, hogy megpróbál üzenetet hozzáadni egy teli várólistához, és soha nem tér vissza.
Ez akkor történik, ha az event azután lép működésbe, hogy a producer ellenőrizte az is_set() feltételt, de még nem lett meghíva a pipeline.set_message() metódus.
Ha ez megtörténik, lehetséges, hogy a producer felébred és kilép, miközben a várólista még mindig teljesen tele van. A producer ekkor meghívja a set_message() metódust, amely megvárja, amíg a várólistán lesz hely az új üzenet számára. A consumer már kilépett, így ez nem fog megtörténni, és a producer sem fog kilépni.
A consumer többi része ismerős lehet.
A Pipeline-on viszont fontos változások történtek:
Python
class Pipeline(queue.Queue):
"""
Osztály, amely lehetővé teszi a termelő és a fogyasztó közötti egyelemű csővezetéket:
"""
def __init__(self):
super().__init__(maxsize=10)
def get_message(self, name):
logging.debug("%s: olvasás a várólistáról", name)
value = self.get()
logging.debug("%s: megkaptam a '%d' üzenetet a queue-től", name, value)
return value
def set_message(self, message, name):
logging.debug("%s: hozzáadom %d-t a queuehez", name, value)
self.put(value)
logging.debug("%s: hozzáadva a sórhoz", name)
Láthatjuk, hogy a Pipeline a queue.Queue alosztálya. A Queue inicializáláskor egy opcionális paraméterrel rendelkezik a queue maximális méretének megadásához.
Ha pozitív számot adsz meg a maxsize értéknek, akkor a várólistát ennyi elemre korlátozza, és a put() addig blokkol, amíg a maxsize értéknél kevesebb elem nem lesz. Ha nem adod meg a maxsize értéket, akkor a várólista a számítógép memóriájának határáig fog nőni.get_message() és set_message() sokkal kisebb lett. Ezek alapvetően a get() és put() metódusokat tartalmazzák a Queue-ből. Talán elgondolkodtál azon, hogy hová tűnt az összes zárolási kód, amely megakadályozza, hogy a szálak versenyfeltételeket okozzanak.
A szabványos könyvtárat író fejlesztők tudták, hogy a Queue-t gyakran használják többszálú környezetben, és az összes zárolási kódot a Queue-ba építették be. A Queue szálbiztos.
A program futtatása a következőképpen néz ki:
Shell
19:19:43: A Producer üzenetet kapot: 25
19:19:43: A Producer üzenetet kapot: 92
19:19:43: A Producer üzenetet kapot: 7
19:19:43: A Producer üzenetet kapot: 35
19:19:43: A Producer üzenetet kapot: 19
19:19:43: A Producer üzenetet kapot: 43
19:19:43: A Producer üzenetet kapot: 50
19:19:43: A Producer üzenetet kapot: 30
19:19:43: A Producer üzenetet kapot: 74
19:19:43: A Producer üzenetet kapot: 48
19:19:43: A Producer üzenetet kapot: 23
19:19:43: Consumer tárolja az üzenetet: 25 (queue mérete: 9)
19:19:43: Consumer tárolja az üzenetet: 92 (queue mérete: 8)
19:19:43: Consumer tárolja az üzenetet: 7 (queue mérete: 7)
19:19:43: Consumer tárolja az üzenetet: 35 (queue mérete: 6)
19:19:43: Consumer tárolja az üzenetet: 19 (queue mérete: 5)
19:19:43: Consumer tárolja az üzenetet: 43 (queue mérete: 4)
19:19:43: Consumer tárolja az üzenetet: 50 (queue mérete: 3)
19:19:43: Consumer tárolja az üzenetet: 30 (queue mérete: 2)
19:19:43: Consumer tárolja az üzenetet: 74 (queue mérete: 1)
19:19:43: Consumer tárolja az üzenetet: 48 (queue mérete: 0)
19:19:43: A Producer üzenetet kapot: 80
19:19:43: A Producer üzenetet kapot: 44
19:19:43: A Producer üzenetet kapot: 34
19:19:43: A Producer üzenetet kapot: 27
19:19:43: A Producer üzenetet kapot: 60
19:19:43: A Producer üzenetet kapot: 98
19:19:43: A Producer üzenetet kapot: 101
19:19:43: A Producer üzenetet kapot: 20
19:19:43: A Producer üzenetet kapot: 93
19:19:43: A Producer üzenetet kapot: 17
19:19:43: Consumer tárolja az üzenetet: 23 (queue mérete: 9)
[ Innen egy csomó üzenetet törőltünk ]
19:19:43: A Producer üzenetet kapot: 25
19:19:43: Consumer tárolja az üzenetet: 19 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 76
19:19:43: Consumer tárolja az üzenetet: 53 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 59
19:19:43: Consumer tárolja az üzenetet: 67 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 81
19:19:43: Consumer tárolja az üzenetet: 81 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 12
19:19:43: Consumer tárolja az üzenetet: 43 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 24
19:19:43: Consumer tárolja az üzenetet: 97 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 5
19:19:43: Consumer tárolja az üzenetet: 60 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 44
19:19:43: Consumer tárolja az üzenetet: 26 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 36
19:19:43: Consumer tárolja az üzenetet: 55 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 11
19:19:43: Consumer tárolja az üzenetet: 80 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 64
19:19:43: Main: set event beállítása
19:19:43: Consumer tárolja az üzenetet: 25 (queue mérete: 9)
19:19:43: A Producer üzenetet kapot: 84
19:19:43: Consumer tárolja az üzenetet: 76 (queue mérete: 9)
19:19:43: Producer EXIT üzenetet kapot. Leáll
19:19:43: Consumer tárolja az üzenetet: 59 (queue mérete: 9)
19:19:43: Consumer tárolja az üzenetet: 81 (queue mérete: 8)
19:19:43: Consumer tárolja az üzenetet: 12 (queue mérete: 7)
19:19:43: Consumer tárolja az üzenetet: 24 (queue mérete: 6)
19:19:43: Consumer tárolja az üzenetet: 5 (queue mérete: 5)
19:19:43: Consumer tárolja az üzenetet: 44 (queue mérete: 4)
19:19:43: Consumer tárolja az üzenetet: 36 (queue mérete: 3)
19:19:43: Consumer tárolja az üzenetet: 11 (queue mérete: 2)
19:19:43: Consumer tárolja az üzenetet: 64 (queue mérete: 1)
19:19:43: Consumer tárolja az üzenetet: 84 (queue mérete: 0)
19:19:43: Consumer EXIT üzenetet kapot. Leáll
Process finished with exit code 0
Ha végigolvasod a példám kimenetét, láthatsz néhány érdekes dolgot. Rögtön a tetején láthatod, hogy a producer 11 üzenetet hozott létre, és közüllük 10 várólistára kerűlt. Ezzel az betelt, a 11-ket már nem tudta berakni a várólistába, így ki lettek cserélve a futó szálak. Lassabb gépeken, komolyabb feladatoknál, vagy csak egy újboli futtatásnál nem biztos, hogy betellik a lista, mielött az operációs rendszer kicserélné a szálakat. Igazából ez lenne az ideális.
A consumer ezután lefutott, és lehúzta az első üzenetet. Kinyomtatta ezt az üzenetet, valamint azt, hogy milyen mély volt a sor az adott ponton:
Shell
19:19:43: Consumer tárolja az üzenetet: 25 (queue mérete: 9)
Ebből tudja, hogy a tizenegyedik üzenet még nem került be a csővezetékbe. A várólista mérete egyetlen üzenet eltávolítása után lecsökkent kilencre.
Megjegyzés: Az ön kimenetele más lett. A kimenet futásról futásra változik. Ez a mókás része a szálakkal való munkának!
Ahogy a program a végefelé közeledik láthatjuk, hogy a fő szál generálja az eseményt (event.set()), ami a producer azonnali kilépését okozza. A consumer-nek még egy csomó munkája van, ezért addig fut, amíg ki nem tisztítja a csővezetéket (pipeline).
Próbáljon meg játszani a különböző várólistaméretekkel és time.sleep() hívásokkal a producer-ben vagy a consumer-ben, hogy hosszabb hálózati vagy lemez-hozzáférési időt szimuláljon. A program ezen elemeit érintő apró változtatások is nagy különbséget jelentenek az eredményekben.
Ez sokkal jobb megoldás a producer-consumer problémára, de még tovább egyszerűsíthetjük. A csővezetékre itt már nincs szükség ennek a problémának a megoldásához. Amint eltávolítjuk a naplózást, egyszerűen csak egy sórt fog foglalni a queue.Queue.
Így néz ki a végleges kód a queue.Queue közvetlen használatával:
Python
import concurrent.futures
import logging
import queue
import random
import threading
import time
def producer(queue, event):
"""Utánozzuk a hálózatról érkező üzeneteket"""
while not event.is_set():
message = random.randint(1, 101)
logging.info("A Producer üzenetet kapot: %s", message)
queue.put(message)
logging.info("Producer EXIT üzenetet kapot. Leáll")
def consumer(queue, event):
"""Itt utánozzuk az adatok adatbázisba írását."""
while not event.is_set() or not queue.empty():
message = queue.get()
logging.info(
"Consumer tárolja az üzenetet: %s (queue mérete: %s)",
message,
queue.qsize()
)
logging.info("Consumer EXIT üzenetet kapot. Leáll")
if __name__ == "__main__":
msg_format = "%(asctime)s: %(message)s"
logging.basicConfig(format=msg_format, level=logging.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=10)
event = threading.Event()
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(producer, pipeline, event)
executor.submit(consumer, pipeline, event)
time.sleep(0.1)
logging.info("Main: set event beállítása")
event.set()
Ez könnyebben olvasható, és megmutatja, hogy a Python beépített primitívjeinek használatával hogyan lehet egyszerűsíteni egy összetett problémát.
A Lock és a Queue praktikus osztályok az egyidejűségi problémák megoldására, de vannak más, a szabványos könyvtár által biztosított osztályok is. Mielőtt befejeznénk ezt a bemutatót, tegyünk egy gyors áttekintést ezek közül néhányról.
Threading objectumok
A Python szálkezelő modulja még néhány további primitív eszközt kínál. Bár a fenti példákhoz nem volt ezekre szükséged, különböző felhasználási esetekben jól jöhetnek, ezért nem árt, ha ismered őket.
Semaphore
Az első Python szálkezelő objektum, amelyet meg kell vizsgálnunk, a threading.Semaphore. A Semaphore egy számláló néhány speciális tulajdonsággal.
Az első az, hogy a számlálás atomikus. Ez azt jelenti, hogy garantált, hogy az operációs rendszer nem cseréli ki a szálat a számláló inkrementálása vagy dekrementálása közben.
A belső számláló a release() metódus hívásakor növekszik, a acquire() hívásakor pedig csökken.
A következő különleges tulajdonság az, hogy ha egy szál akkor hívja meg a acquire() parancsot, amikor a számláló nulla, akkor az a szál addig blokkol, amíg egy másik szál meg nem hívja a .release() parancsot, és a számlálót eggyel nem növeli.
A szemaforokat gyakran használják egy korlátozott kapacitású erőforrás védelmére. Ilyen például, ha van egy kapcsolatállományunk, és ennek méretét egy meghatározott számra szeretnénk korlátozni.
Timer
A threading.Timer egy módja annak, hogy egy függvényt úgy ütemezzünk be, hogy egy bizonyos idő elteltével meghívásra kerüljön. A Timer létrehozásához megadjuk a várandó másodpercek számát és a meghívandó függvényt:
Python
t = threading.Timer(30.0, my_function)
Az időzítőt a start() hívásával indítjuk el. A függvény egy új szálon fog meghívásra kerülni a megadott idő után valamikor, de vedd figyelembe, hogy nem garantált a pontosan időpontban történő meghívás.
Ha egy már elindított időzítőt le akarsz állítani, akkor a cancel() hívásával állíthatod le. A cancel() hívása az időzítő elindulása után nem eredményez semmit, és nem produkál kivételt.
Az időzítő arra használható, hogy egy adott idő elteltével cselekvésre szólítsa fel a felhasználót. Ha a felhasználó az időzítő lejárta előtt elvégzi a műveletet, akkor a cancel() hívható.
Barrier
Egy threading.Barrier használható a meghatározott számú szálak szinkronban tartására. A Barrier létrehozásakor a hívónak meg kell adnia, hogy hány szál fog szinkronizálni rajta. Minden szál meghívja a wait() metódust a Barrier-en. Mind addig maradnak blokkolva, amíg a megadott számú szál várakozik, majd egyszerre felszabadulnak.
Ne feledje, hogy a szálakat az operációs rendszer ütemezi, így még ha az összes szál egyszerre is szabadul fel, azok egyenként lesznek ütemezve.
A Barrier egyik felhasználási módja, hogy lehetővé tegye a szálak egy csoportjának, hogy inicializálják magukat. Azzal, hogy a szálak várakoznak egy akadályon, miután inicializálódtak, biztosítható, hogy egyik szál sem kezd el futni, mielőtt az összes szál befejezte volna az inicializálást.
Következtetés: Threading a Python-ban
Mostanra már sokat láttál abból, amit a Python szálkezelés kínál, és láttál néhány példát arra, hogyan lehet szálkezelt programokat készíteni, és milyen problémákat oldanak meg. Láttál néhány példát arra is, hogy milyen problémák merülnek fel a többszálú programok írása és hibakeresése során.
Ha szeretnél más lehetőségeket is felfedezni az egyidejűségre Pythonban, nézd meg a Speed Up Your Python Program With Concurrency című angol nyelvű cikket.
Ha érdekel az asyncio modul mélyebb megismerése, olvasd el az Async IO in Python: A Complete Walkthrough című angol nyelvű cikket.
Bármit is teszel, most már rendelkezel a szükséges információkkal és magabiztossággal ahhoz, hogy programokat írj a Python szálak használatával!
Még egyszer külön köszönet a RealPython oldalnak e remek cikkért. További érdekes tartalmak felkereséséért érdemes meglátogatni.